for td in table: item = {} # 定义一个字典存放字段 item['word'] = td.find('td',class_='span2').find('strong').text item['translate'] = ''.join(td.find('td', class_='span10').text.split('\n')) items.append(item) # 添加到列表中
3.由主链接获取相关链接,然后迭代调用 get_info()
1 2 3 4 5 6 7 8 9 10 11
defget_links(url): html = get_html(url) soup = BeautifulSoup(html, 'lxml') td = soup.find_all('td', class_='wordbook-wordlist-name') for a in td: link = a.find('a')['href'] for i inrange(1,11): links.append('https://www.shanbay.com' + link + '?page=' + str(i))
for link in links: get_info(link)
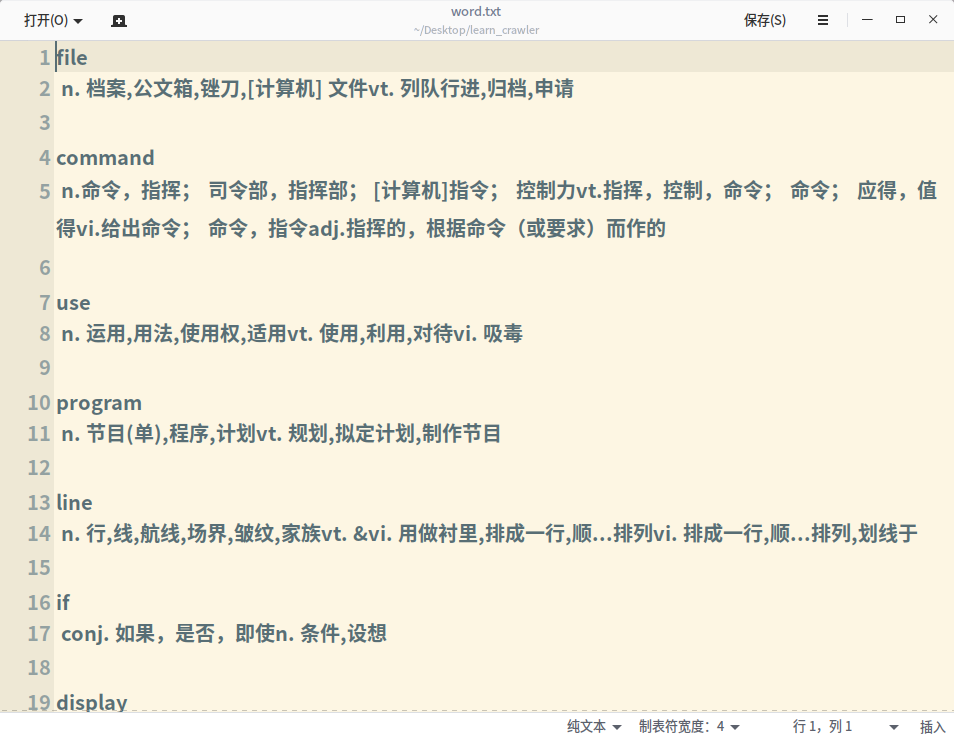
4.把解析的内容下载到本地
1 2 3 4 5
defdown_info(): withopen('./word.txt', 'w') as f: for item in items: f.write(item['word'] + '\n' + item['translate'] + '\n\n') print('Download finished!\n共{}个'.format(len(items)))